Case Study 1: Full-length Dataset
The processed full-length human PBMC dataset can be downloaded from this link
[1]:
from DOLPHIN.model import run_DOLPHIN
import numpy as np
/mnt/data/kailu9/miniconda3/envs/DOLPHIN/lib/python3.10/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Step 1: Get Cell Embedding
FeatureCompHvg_[sample].h5ad (fsla_FeatureCompHvg.h5ad)
model_[sample].pt (fsla_geometric.pt)
These files contain the high-variable gene expression matrix and the precomputed cell-cell graph, respectively.
[ ]:
#load datasets
graph_data = "fsla_geometric.pt"
feature_data = "fsla_FeatureCompHvg.h5ad"
## save the output adata, default is set to the current folder
output_path = './'
[4]:
run_DOLPHIN("full-length", graph_data, feature_data, output_path, seed_num=11)
/mnt/md1/kailu/DOLPHIN/DOLPHIN/model/train.py:35: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
pg_celldata = torch.load(in_path_gp)
[epoch 000] training loss: 115338.2117
[epoch 001] training loss: 81771.5766
[epoch 002] training loss: 74215.9434
[epoch 003] training loss: 71437.4215
[epoch 004] training loss: 69656.1832
[epoch 005] training loss: 68168.9158
[epoch 006] training loss: 66829.5367
[epoch 007] training loss: 65616.5880
[epoch 008] training loss: 64448.0012
[epoch 009] training loss: 63297.8623
[epoch 010] training loss: 62200.4691
[epoch 011] training loss: 61120.9869
[epoch 012] training loss: 60076.0659
[epoch 013] training loss: 59048.0559
[epoch 014] training loss: 58052.7569
[epoch 015] training loss: 57068.4969
[epoch 016] training loss: 56111.4685
[epoch 017] training loss: 55167.6413
[epoch 018] training loss: 54247.1174
[epoch 019] training loss: 53342.0114
[epoch 020] training loss: 52452.9016
[epoch 021] training loss: 51582.7058
[epoch 022] training loss: 50729.5766
[epoch 023] training loss: 49884.5769
[epoch 024] training loss: 49059.4285
[epoch 025] training loss: 48251.2288
[epoch 026] training loss: 47455.4444
[epoch 027] training loss: 46672.9205
[epoch 028] training loss: 45905.0286
[epoch 029] training loss: 45151.4555
[epoch 030] training loss: 44413.5624
[epoch 031] training loss: 43688.7728
[epoch 032] training loss: 42976.9259
[epoch 033] training loss: 42278.4061
[epoch 034] training loss: 41589.1830
[epoch 035] training loss: 40916.3747
[epoch 036] training loss: 40259.2950
[epoch 037] training loss: 39611.1651
[epoch 038] training loss: 38974.8843
[epoch 039] training loss: 38350.4938
[epoch 040] training loss: 37740.9330
[epoch 041] training loss: 37141.7601
[epoch 042] training loss: 36549.9488
[epoch 043] training loss: 35971.5089
[epoch 044] training loss: 35405.1161
[epoch 045] training loss: 34850.4354
[epoch 046] training loss: 34306.2577
[epoch 047] training loss: 33772.3445
[epoch 048] training loss: 33247.8514
[epoch 049] training loss: 32735.0963
[epoch 050] training loss: 32229.5945
[epoch 051] training loss: 31734.3237
[epoch 052] training loss: 31248.8923
[epoch 053] training loss: 30775.1097
[epoch 054] training loss: 30308.0289
[epoch 055] training loss: 29849.5355
[epoch 056] training loss: 29402.4283
[epoch 057] training loss: 28962.4901
[epoch 058] training loss: 28534.5269
[epoch 059] training loss: 28109.3743
[epoch 060] training loss: 27694.8668
[epoch 061] training loss: 27287.9266
[epoch 062] training loss: 26888.9853
[epoch 063] training loss: 26498.4149
[epoch 064] training loss: 26113.7431
[epoch 065] training loss: 25736.2456
[epoch 066] training loss: 25367.5909
[epoch 067] training loss: 25007.1149
[epoch 068] training loss: 24650.7476
[epoch 069] training loss: 24302.9563
[epoch 070] training loss: 23963.2115
[epoch 071] training loss: 23628.1815
[epoch 072] training loss: 23300.3074
[epoch 073] training loss: 22977.3982
[epoch 074] training loss: 22664.6817
[epoch 075] training loss: 22354.9118
[epoch 076] training loss: 22050.4605
[epoch 077] training loss: 21752.3034
[epoch 078] training loss: 21459.2315
[epoch 079] training loss: 21173.1089
[epoch 080] training loss: 20890.4574
[epoch 081] training loss: 20616.0347
[epoch 082] training loss: 20343.7687
[epoch 083] training loss: 20080.9915
[epoch 084] training loss: 19821.1775
[epoch 085] training loss: 19566.8088
[epoch 086] training loss: 19312.0427
[epoch 087] training loss: 19067.5650
[epoch 088] training loss: 18825.8958
[epoch 089] training loss: 18589.8234
[epoch 090] training loss: 18357.4422
[epoch 091] training loss: 18129.1278
[epoch 092] training loss: 17905.0552
[epoch 093] training loss: 17687.7221
[epoch 094] training loss: 17469.5163
[epoch 095] training loss: 17260.8215
[epoch 096] training loss: 17053.2891
[epoch 097] training loss: 16852.9382
[epoch 098] training loss: 16650.7976
[epoch 099] training loss: 16451.4710
[epoch 100] training loss: 16260.0131
[epoch 101] training loss: 16072.4849
[epoch 102] training loss: 15887.2649
[epoch 103] training loss: 15705.7171
[epoch 104] training loss: 15525.0017
[epoch 105] training loss: 15350.4742
[epoch 106] training loss: 15177.9547
[epoch 107] training loss: 15008.9613
[epoch 108] training loss: 14843.5931
[epoch 109] training loss: 14680.5648
[epoch 110] training loss: 14520.8382
[epoch 111] training loss: 14362.8159
[epoch 112] training loss: 14208.2686
[epoch 113] training loss: 14058.5771
[epoch 114] training loss: 13907.7038
[epoch 115] training loss: 13762.3002
[epoch 116] training loss: 13619.1935
[epoch 117] training loss: 13480.7669
[epoch 118] training loss: 13343.1430
[epoch 119] training loss: 13205.6363
[epoch 120] training loss: 13073.5108
[epoch 121] training loss: 12941.1051
[epoch 122] training loss: 12813.6108
[epoch 123] training loss: 12689.4540
[epoch 124] training loss: 12562.3935
[epoch 125] training loss: 12441.9435
[epoch 126] training loss: 12321.9635
[epoch 127] training loss: 12205.1154
[epoch 128] training loss: 12088.5721
[epoch 129] training loss: 11971.6848
[epoch 130] training loss: 11859.6795
[epoch 131] training loss: 11753.4818
[epoch 132] training loss: 11645.0735
[epoch 133] training loss: 11537.2579
[epoch 134] training loss: 11434.7437
[epoch 135] training loss: 11333.3309
[epoch 136] training loss: 11231.6057
[epoch 137] training loss: 11132.9543
[epoch 138] training loss: 11034.8078
[epoch 139] training loss: 10939.2346
[epoch 140] training loss: 10846.3600
[epoch 141] training loss: 10755.2664
[epoch 142] training loss: 10664.1102
[epoch 143] training loss: 10572.9778
[epoch 144] training loss: 10486.1590
[epoch 145] training loss: 10402.8069
[epoch 146] training loss: 10318.6806
[epoch 147] training loss: 10235.2428
[epoch 148] training loss: 10154.0632
[epoch 149] training loss: 10070.6796
[epoch 150] training loss: 9992.3465
[epoch 151] training loss: 9917.1646
[epoch 152] training loss: 9840.1296
[epoch 153] training loss: 9764.4478
[epoch 154] training loss: 9689.1771
[epoch 155] training loss: 9617.3009
[epoch 156] training loss: 9545.4596
[epoch 157] training loss: 9477.5416
[epoch 158] training loss: 9410.3500
[epoch 159] training loss: 9342.3141
[epoch 160] training loss: 9274.2874
[epoch 161] training loss: 9209.2197
[epoch 162] training loss: 9142.5287
[epoch 163] training loss: 9080.0836
[epoch 164] training loss: 9018.7819
[epoch 165] training loss: 8955.6917
[epoch 166] training loss: 8897.9084
[epoch 167] training loss: 8839.8252
[epoch 168] training loss: 8780.9362
[epoch 169] training loss: 8724.4193
[epoch 170] training loss: 8665.1323
[epoch 171] training loss: 8609.9548
[epoch 172] training loss: 8555.3133
[epoch 173] training loss: 8500.9404
[epoch 174] training loss: 8445.6331
[epoch 175] training loss: 8397.8491
[epoch 176] training loss: 8344.7480
[epoch 177] training loss: 8294.3846
[epoch 178] training loss: 8245.5878
[epoch 179] training loss: 8198.0013
[epoch 180] training loss: 8148.8633
[epoch 181] training loss: 8102.4537
[epoch 182] training loss: 8056.0749
[epoch 183] training loss: 8010.3959
[epoch 184] training loss: 7965.1029
[epoch 185] training loss: 7922.9981
[epoch 186] training loss: 7880.4463
[epoch 187] training loss: 7838.7793
[epoch 188] training loss: 7795.8751
[epoch 189] training loss: 7754.1590
[epoch 190] training loss: 7712.9806
[epoch 191] training loss: 7670.7201
[epoch 192] training loss: 7632.2103
[epoch 193] training loss: 7593.3752
[epoch 194] training loss: 7553.5104
[epoch 195] training loss: 7517.5185
[epoch 196] training loss: 7480.5194
[epoch 197] training loss: 7445.6976
[epoch 198] training loss: 7408.1459
[epoch 199] training loss: 7373.1576
[5]:
import scanpy as sc
from sklearn.metrics import adjusted_rand_score
The result is saved at this link
[ ]:
adata = sc.read_h5ad("./DOLPHIN_Z.h5ad")
[11]:
sc.pp.neighbors(adata, use_rep="X_z")
sc.tl.umap(adata)
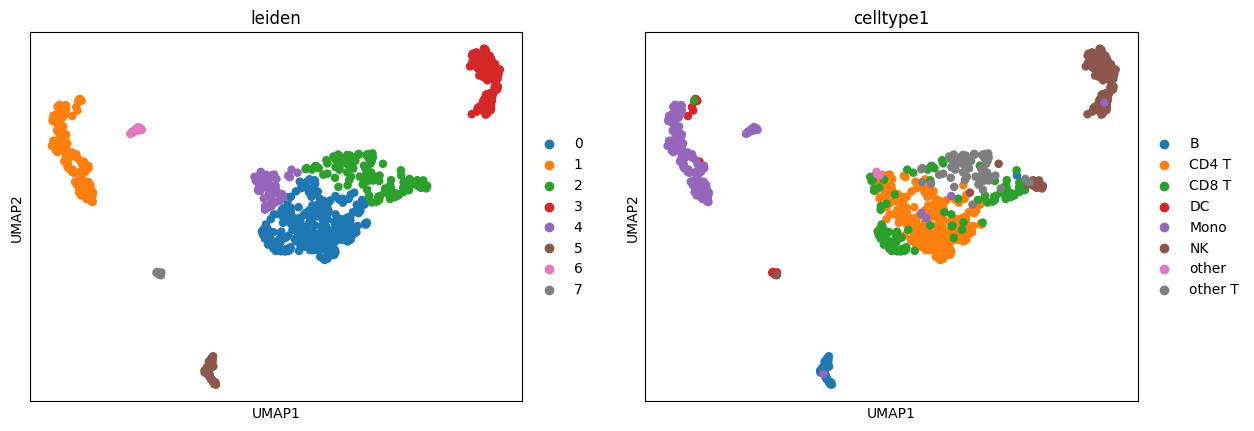
sc.tl.leiden(adata, 0.7, random_state=0)
print(len(set(adata.obs["leiden"])))
adjusted_rand_score(adata.obs["predicted.celltype.l1"], adata.obs["leiden"])
8
[11]:
0.6530821397755997
[12]:
sc.pl.umap(adata, color=['leiden', "predicted.celltype.l1"], wspace=0.5)
Step 2: Alternative Splicing Analysis
DOLPHIN begins with cell embeddings that cluster cells sharing similar exon and junction patterns. Based on these embeddings, DOLPHIN aggregates reads from neighboring cells to improve signal for downstream splicing analysis.
For the cell aggregation step, please refer to the tutorial here.
For running alternative splicing detection using Outrigger, follow the instructions in the tutorial here.
[10]:
import scanpy as sc
import numpy as np
[ ]:
## adata version of psi matrix generated directly from Outrigger
adata_psi = sc.read_h5ad("./alternative_splicing/fsla_PSI.h5ad")
Step 2-1: Number of Splicing Events Detected
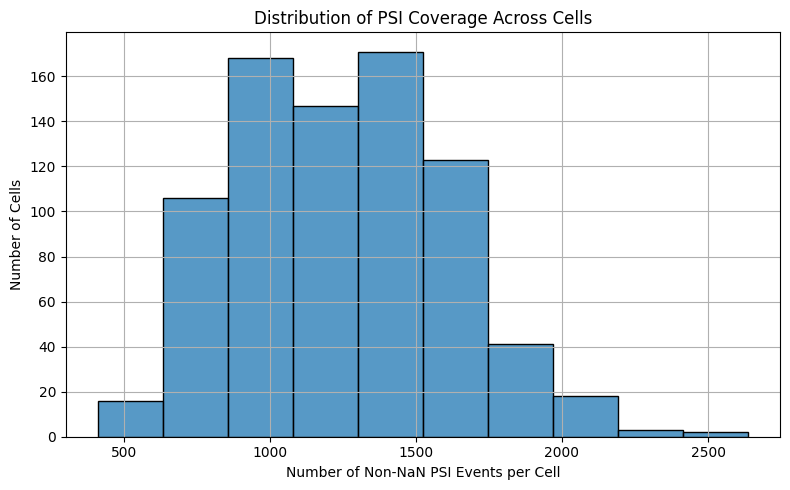
In this step, we evaluate the number of splicing events (combined ES and MXE) detected per cell. A splicing event is considered “detected” if it has a valid (non-NaN) PSI value. This gives an overview of the coverage and completeness of splicing information across the dataset.
[ ]:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
psi_df = adata_psi.to_df()
# Count non-NaN PSI values per cell (row-wise)
non_nan_counts = psi_df.notna().sum(axis=1)
# Plot histogram
plt.figure(figsize=(8, 5))
sns.histplot(non_nan_counts, bins=10, kde=False)
plt.xlabel("Number of Non-NaN PSI Events per Cell")
plt.ylabel("Number of Cells")
plt.title("Distribution of PSI Coverage Across Cells")
plt.grid(True)
plt.tight_layout()
plt.show()
Step 2-2: Cell Clustering Using PSI Values
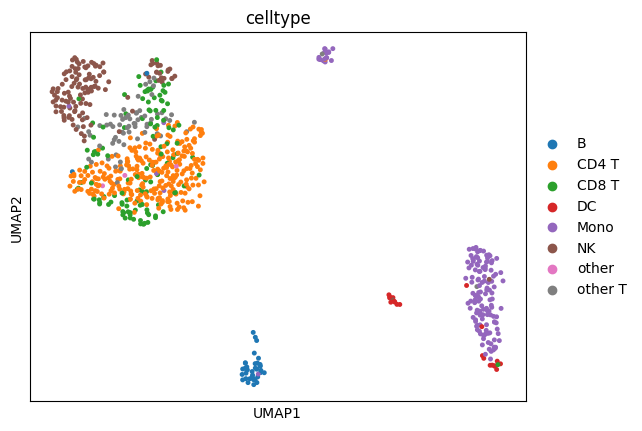
In this step, we use the adata_psi_random dataset. These PSI values represent alternative splicing patterns and are used to identify clusters of cells with similar splicing profiles.
[ ]:
adata_psi_random = sc.read_h5ad("./alternative_splicing/fsla_PSI_random.h5ad")
## get cluster
sc.tl.pca(adata_psi_random, svd_solver='arpack')
sc.pp.neighbors(adata_psi_random)
sc.tl.umap(adata_psi_random)
for res in np.arange(0.0,2,0.01):
sc.tl.leiden(adata_psi_random, res, random_state=0)
if len(set(adata_psi_random.obs["leiden"])) == len(set(adata_psi_random.obs["celltype1"])):
break
print(len(set(adata_psi_random.obs["leiden"])))
sc.pl.umap(adata_psi_random, color=["celltype1"], show=False, s=50)
8
<Axes: title={'center': 'celltype'}, xlabel='UMAP1', ylabel='UMAP2'>
Step 2-3: Differential Alternative Splicing
In this step, we use the adata_psi_DAS.h5ad file to perform differential alternative splicing analysis.
[ ]:
adata_psi_DAS = sc.read_h5ad("./alternative_splicing/fsla_PSI_DAS.h5ad")
[22]:
adata_psi_DAS.var["new_name"] = adata_psi_DAS.var.index
adata_psi_DAS.var["new_name"] = adata_psi_DAS.var["new_name"].astype(str) + '|Gene' + adata_psi_DAS.var["gene_name"].astype(str)
adata_psi_DAS.var["event"] = adata_psi_DAS.var.index
adata_psi_DAS.var = adata_psi_DAS.var.set_index("new_name")
adata_psi_DAS.var.index.name=None
[26]:
sc.tl.rank_genes_groups(adata_psi_DAS, 'celltype1', method='wilcoxon', key_added="psi_DAS_wilcoxon")
[27]:
sc.pl.rank_genes_groups_dotplot(adata_psi_DAS, key="psi_DAS_wilcoxon", n_genes=10, standard_scale='var', swap_axes=True, show=False)
WARNING: dendrogram data not found (using key=dendrogram_celltype1). Running `sc.tl.dendrogram` with default parameters. For fine tuning it is recommended to run `sc.tl.dendrogram` independently.
/mnt/data/kailu9/miniconda3/envs/DOLPHIN/lib/python3.10/site-packages/scanpy/tools/_utils.py:41: UserWarning: You’re trying to run this on 4978 dimensions of `.X`, if you really want this, set `use_rep='X'`.
Falling back to preprocessing with `sc.pp.pca` and default params.
warnings.warn(
[27]:
{'mainplot_ax': <Axes: >,
'group_extra_ax': <Axes: >,
'gene_group_ax': <Axes: >,
'size_legend_ax': <Axes: title={'center': 'Fraction of cells\nin group (%)'}>,
'color_legend_ax': <Axes: title={'center': 'Mean expression\nin group'}>}
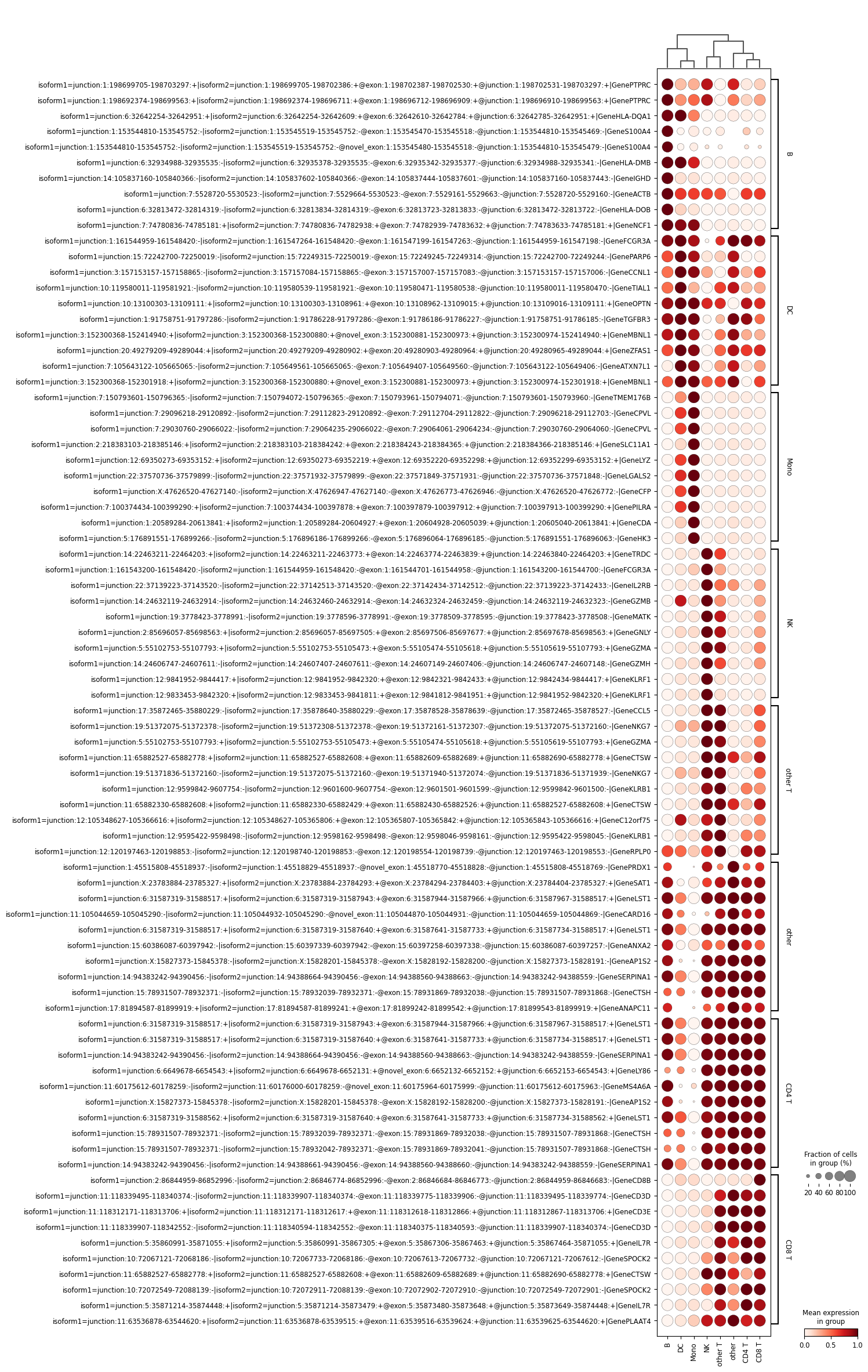
Step 2-4: Alternative Splicing Modality Analysis
In this step, we perform alternative splicing modality analysis using the anchor module from the Expedition suite. This tool identifies the distributional modality of splicing events (e.g., bimodal, unimodal) across single cells.
To use this function, please make sure to install the anchor module as instructed in the official tutorial.
[26]:
import anchor
import anndata
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
[ ]:
adata_psi = anndata.read_h5ad("./alternative_splicing/fsla_PSI.h5ad")
psi_df = adata_psi.to_df()
[ ]:
for i, _type in enumerate(list(set(adata_psi.obs["celltype1"]))):
## get the list of cell names in each cell type
print(_type)
current_sample_list = list(adata_psi.obs[adata_psi.obs["celltype1"] == _type].index)
data_sub = psi_df.loc[current_sample_list]
#run anchor
bm = anchor.BayesianModalities()
current_modal = bm.fit_predict(data_sub)
df_temp = pd.DataFrame(current_modal, columns=[_type])
if i == 0:
df_mod = df_temp
else:
df_mod = pd.merge(df_mod, df_temp, left_index=True, right_index=True)
DC
CD4 T
B
CD8 T
other
NK
other T
Mono
[22]:
df_mod
[22]:
| DC | CD4T | B | CD8T | other | NK | otherT | Mono | |
|---|---|---|---|---|---|---|---|---|
| isoform1=junction:10:100246936-100253420:-|isoform2=junction:10:100250333-100253420:-@exon:10:100250248-100250332:-@junction:10:100246936-100250247:- | NaN | uncategorized | NaN | NaN | NaN | NaN | uncategorized | NaN |
| isoform1=junction:10:100256477-100260965:-|isoform2=junction:10:100260320-100260965:-@exon:10:100260218-100260319:-@junction:10:100256477-100260217:- | NaN | NaN | NaN | uncategorized | NaN | NaN | NaN | NaN |
| isoform1=junction:10:100489762-100490705:-|isoform2=junction:10:100490323-100490705:-@exon:10:100490008-100490322:-@junction:10:100489762-100490007:- | NaN | uncategorized | NaN | NaN | NaN | NaN | uncategorized | NaN |
| isoform1=junction:10:100496432-100497666:-|isoform2=junction:10:100497281-100497666:-@exon:10:100497135-100497280:-@junction:10:100496432-100497134:- | NaN | uncategorized | NaN | NaN | NaN | uncategorized | NaN | NaN |
| isoform1=junction:10:100498208-100499159:-|isoform2=junction:10:100498805-100499159:-@exon:10:100498705-100498804:-@junction:10:100498208-100498704:- | NaN | uncategorized | NaN | NaN | NaN | uncategorized | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| isoform1=junction:X:2723365-2738199:+@exon:X:2738200-2738256:+@junction:X:2738257-2740778:+|isoform2=junction:X:2723365-2726259:+@exon:X:2726260-2726373:+@junction:X:2726374-2740778:+ | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| isoform1=junction:X:41342837-41343736:+@exon:X:41343737-41343822:+@junction:X:41343823-41344029:+|isoform2=junction:X:41342837-41343215:+@exon:X:41343216-41343351:+@junction:X:41343352-41344029:+ | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| isoform1=junction:X:47657291-47657781:-@exon:X:47657183-47657290:-@junction:X:47652145-47657182:-|isoform2=junction:X:47657640-47657781:-@exon:X:47657572-47657639:-@junction:X:47652145-47657571:- | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| isoform1=junction:X:47657291-47657781:-@novel_exon:X:47657205-47657290:-@junction:X:47652145-47657204:-|isoform2=junction:X:47657640-47657781:-@exon:X:47657572-47657639:-@junction:X:47652145-47657571:- | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| isoform1=junction:X:78945496-78952192:+@exon:X:78952193-78952335:+@junction:X:78952336-78960507:+|isoform2=junction:X:78945496-78947814:+@exon:X:78947815-78947863:+@junction:X:78947864-78960507:+ | NaN | NaN | NaN | NaN | NaN | uncategorized | NaN | NaN |
9487 rows × 8 columns
[ ]:
#save the modality results
df_mod.to_csv("./modality.csv")
[23]:
## Plot the modality result
plt_event = psi_df.T.stack().reset_index(name='psi').rename(columns={"level_0":"event_id", "level_1":"cell_name"})
plt_event = pd.merge(plt_event, pd.DataFrame(adata_psi.obs), left_on="cell_name", right_index=True)
[24]:
event_name = "isoform1=junction:1:198699705-198703297:+|isoform2=junction:1:198699705-198702386:+@exon:1:198702387-198702530:+@junction:1:198702531-198703297:+"
plt_final = plt_event[plt_event["event_id"] == event_name]
plt_final["Modality"] = plt_final["celltype1"]
plt_final['Modality'] = plt_final['Modality'].apply(lambda x: x.replace(' ', ''))
mod_label = df_mod.loc[event_name].to_dict()
plt_final = plt_final.replace({"Modality": mod_label})
/tmp/ipykernel_914322/1683559342.py:3: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
plt_final["Modality"] = plt_final["celltype1"]
/tmp/ipykernel_914322/1683559342.py:4: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
plt_final['Modality'] = plt_final['Modality'].apply(lambda x: x.replace(' ', ''))
[27]:
ax = sns.boxplot(plt_final, x="celltype1", y="psi", hue="Modality", palette=["#B5C6E7", "#C6E1B8", "#F9B3AD", "#F8CDAD", "#E42320"])
sns.stripplot(data = plt_final, x = "celltype1", y = "psi", s=2, linewidth=0, dodge=True, jitter=0.3, hue="Modality", edgecolor= ["#4474C4", "#6FAE45", "#C74546", "#EF7E33", "#FFC101"],palette=["#4474C4", "#6FAE45", "#C74546", "#EF7E33", "#FFC101"]).set_title("PTPRC:HsaEX0051104")
sns.move_legend(ax, "upper left", bbox_to_anchor=(1, 1))
plt.show()
/tmp/ipykernel_914322/3399849914.py:2: UserWarning: The palette list has more values (5) than needed (4), which may not be intended.
sns.stripplot(data = plt_final, x = "celltype1", y = "psi", s=2, linewidth=0, dodge=True, jitter=0.3, hue="Modality", edgecolor= ["#4474C4", "#6FAE45", "#C74546", "#EF7E33", "#FFC101"],palette=["#4474C4", "#6FAE45", "#C74546", "#EF7E33", "#FFC101"]).set_title("PTPRC:HsaEX0051104")
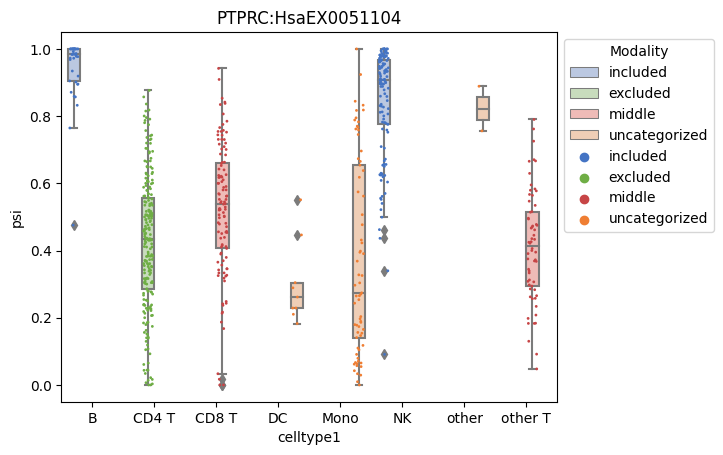
In this step, we use splicing modality patterns to cluster cells. Each splicing event’s modality (e.g., included, excluded, bimodal, etc.) is converted into a one-hot encoded format. This binary representation allows us to use standard clustering techniques to group cells based on shared splicing modalities.
[1]:
from DOLPHIN.AS.convert_modality_ohe import run_modality_ohe
[2]:
adata_psi_modality_ohe = run_modality_ohe(
anchor_output = "./modality.csv",
adata_psi = "./alternative_splicing/fsla_PSI.h5ad",
cluster_name = "celltype1",
out_directory = "./fsla_PSI_modality_ohe.h5ad"
)
/mnt/data/kailu9/DOLPHIN/DOLPHIN/AS/convert_modality_ohe.py:43: FutureWarning: Downcasting behavior in `replace` is deprecated and will be removed in a future version. To retain the old behavior, explicitly call `result.infer_objects(copy=False)`. To opt-in to the future behavior, set `pd.set_option('future.no_silent_downcasting', True)`
df_mod_num = df_mod.replace(dict_mod_num)
DC
CD4 T
B
CD8 T
other
NK
other T
Mono
[4]:
adata_psi_modality_ohe
[4]:
AnnData object with n_obs × n_vars = 795 × 9487
obs: 'celltype1', 'celltype2'
[7]:
import scanpy as sc
import numpy as np
sc.tl.pca(adata_psi_modality_ohe, svd_solver='arpack')
sc.pp.neighbors(adata_psi_modality_ohe, n_neighbors=20, n_pcs=40)
sc.tl.umap(adata_psi_modality_ohe, min_dist=0.2,spread=1.5)
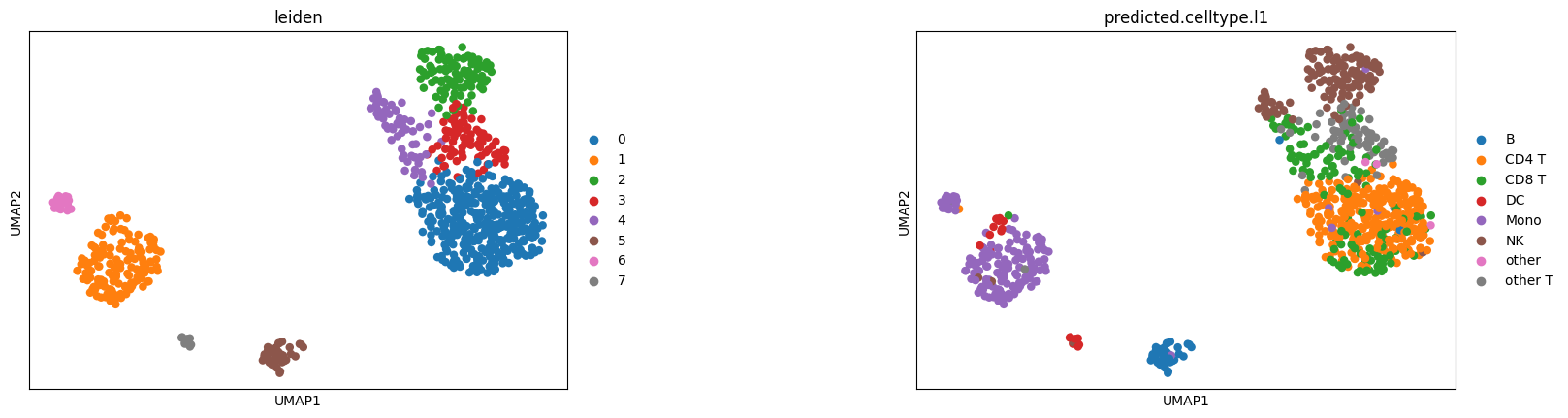
for res in np.arange(0.0,2,0.1):
sc.tl.leiden(adata_psi_modality_ohe, res, random_state=0)
if len(set(adata_psi_modality_ohe.obs["leiden"])) == len(set(adata_psi_modality_ohe.obs["celltype1"])):
break
/tmp/ipykernel_951566/818419519.py:7: FutureWarning: In the future, the default backend for leiden will be igraph instead of leidenalg.
To achieve the future defaults please pass: flavor="igraph" and n_iterations=2. directed must also be False to work with igraph's implementation.
sc.tl.leiden(adata_psi_modality_ohe, res, random_state=0)
[9]:
sc.pl.umap(adata_psi_modality_ohe, color=['leiden','celltype1'])