Exon GTF Generation
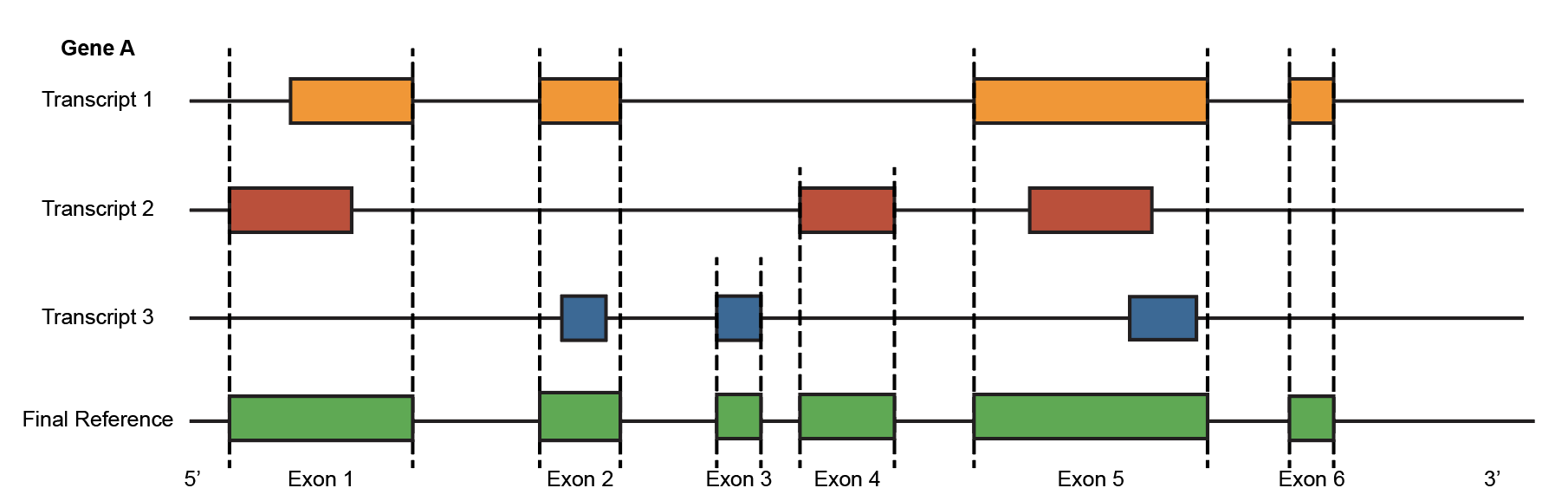
This guide explains how to generate an exon-level GTF reference file. This file is used to align scRNA-seq data to the exon level, allowing the extraction of exon read counts and junction read counts. The goal of the exon-level GTF is to ensure that exons within each gene are unique and do not overlap with one another.
For Human GRCh38
You can directly download the pre-generated exon-level GTF file from here.
For Other Species
First, download the reference GTF file from here.
Then, run this script to generate the exon-level GTF file.
[5]:
from DOLPHIN.preprocess import generate_nonoverlapping_exons
import os
[3]:
# === Step 1: Set paths ===
# Define the output directory
output_path = "./"
# Path to the input Ensembl GTF file
input_gtf_path = "/mnt/md0/kailu/Apps/ensembl_hg38/Homo_sapiens.GRCh38.107.gtf"
[4]:
gtf_df, overlaps = generate_nonoverlapping_exons(input_gtf_path, output_path)
[Step] Reading GTF file from: /mnt/md0/kailu/Apps/ensembl_hg38/Homo_sapiens.GRCh38.107.gtf
[Status] GTF loaded and parsed with 3371244 total entries.
[Status] Removed duplicates: 674296 unique exon entries remain.
[Step] Start processing and saving exons by batch...
Processing all genes: 100%|██████████| 61860/61860 [1:16:37<00:00, 13.46it/s]
[Done] Finished saving all exon batches.
Successfully combined 7 files into a single DataFrame with 354386 rows.
Found 0 overlapping exon entries.
All 61860 expected genes are present in the merged DataFrame.
/mnt/md1/kailu/DOLPHIN/DOLPHIN/preprocess/gtfpy.py:108: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
df['attribute']=""
/mnt/md1/kailu/DOLPHIN/DOLPHIN/preprocess/gtfpy.py:113: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
df['attribute']=df['attribute']+c+' "'+inGTF[c].astype(str)+'"; '
/mnt/md1/kailu/DOLPHIN/DOLPHIN/preprocess/gtfpy.py:113: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
df['attribute']=df['attribute']+c+' "'+inGTF[c].astype(str)+'"; '
/mnt/md1/kailu/DOLPHIN/DOLPHIN/preprocess/gtfpy.py:113: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
df['attribute']=df['attribute']+c+' "'+inGTF[c].astype(str)+'"; '
/mnt/md1/kailu/DOLPHIN/DOLPHIN/preprocess/gtfpy.py:113: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
df['attribute']=df['attribute']+c+' "'+inGTF[c].astype(str)+'"; '
/mnt/md1/kailu/DOLPHIN/DOLPHIN/preprocess/gtfpy.py:113: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
df['attribute']=df['attribute']+c+' "'+inGTF[c].astype(str)+'"; '
/mnt/md1/kailu/DOLPHIN/DOLPHIN/preprocess/gtfpy.py:111: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
df['attribute']=df['attribute']+c+' "'+inGTF[c].astype(str)+'";'
GTF file saved to: ./dolphin_exon_gtf/dolphin.exon.gtf
Pickle file saved to: ./dolphin_exon_gtf/./dolphin.exon.pkl
[Success] Exon GTF processing pipeline completed.
Generate Adjacency Index
This step computes a per-gene adjacency index based on the exon annotation (.pkl converted from GTF). The result is used to locate each gene’s exon adjacency matrix in the full graph structure.
[3]:
from DOLPHIN.preprocess import generate_adj_index_table
[5]:
exon_pkl_path= "./dolphin_exon_gtf/dolphin.exon.pkl"
df_adj_index = generate_adj_index_table(exon_pkl_path)
[Saved] Adjacency index table saved to: ./dolphin_exon_gtf/dolphin_adj_index.csv
[6]:
df_adj_index
[6]:
| geneid | ind_st | ind | |
|---|---|---|---|
| 0 | ENSG00000223972 | 0.0 | 16.0 |
| 1 | ENSG00000227232 | 16.0 | 121.0 |
| 2 | ENSG00000278267 | 137.0 | 1.0 |
| 3 | ENSG00000243485 | 138.0 | 9.0 |
| 4 | ENSG00000284332 | 147.0 | 1.0 |
| ... | ... | ... | ... |
| 61855 | ENSG00000224240 | 6529063.0 | 1.0 |
| 61856 | ENSG00000227629 | 6529064.0 | 9.0 |
| 61857 | ENSG00000237917 | 6529073.0 | 169.0 |
| 61858 | ENSG00000231514 | 6529242.0 | 1.0 |
| 61859 | ENSG00000235857 | 6529243.0 | 1.0 |
61860 rows × 3 columns
[1]:
from DOLPHIN.preprocess import generate_adj_metadata_table
[3]:
df_adj_index_meta, df_gene_meta = generate_adj_metadata_table(exon_pkl_path)
[Saved] Adjacency metadata table saved to: ./dolphin_exon_gtf/dolphin_adj_metadata_table.csv
[Saved] Gene metadata table saved to: ./dolphin_exon_gtf/dolphin_gene_meta.csv
[4]:
df_adj_index_meta
[4]:
| Geneid | GeneName | Gene_Junc_name | |
|---|---|---|---|
| 0 | ENSG00000223972 | DDX11L1 | DDX11L1-1 |
| 1 | ENSG00000223972 | DDX11L1 | DDX11L1-2 |
| 2 | ENSG00000223972 | DDX11L1 | DDX11L1-3 |
| 3 | ENSG00000223972 | DDX11L1 | DDX11L1-4 |
| 4 | ENSG00000223972 | DDX11L1 | DDX11L1-5 |
| ... | ... | ... | ... |
| 6529239 | ENSG00000237917 | PARP4P1 | PARP4P1-167 |
| 6529240 | ENSG00000237917 | PARP4P1 | PARP4P1-168 |
| 6529241 | ENSG00000237917 | PARP4P1 | PARP4P1-169 |
| 6529242 | ENSG00000231514 | CCNQP2 | CCNQP2-1 |
| 6529243 | ENSG00000235857 | CTBP2P1 | CTBP2P1-1 |
6529244 rows × 3 columns
[5]:
df_gene_meta
[5]:
| gene_id | gene_name | |
|---|---|---|
| 0 | ENSG00000223972 | DDX11L1 |
| 1 | ENSG00000227232 | WASH7P |
| 2 | ENSG00000278267 | MIR6859-1 |
| 3 | ENSG00000243485 | MIR1302-2HG |
| 4 | ENSG00000284332 | MIR1302-2 |
| ... | ... | ... |
| 61855 | ENSG00000224240 | CYCSP49 |
| 61856 | ENSG00000227629 | SLC25A15P1 |
| 61857 | ENSG00000237917 | PARP4P1 |
| 61858 | ENSG00000231514 | CCNQP2 |
| 61859 | ENSG00000235857 | CTBP2P1 |
61860 rows × 2 columns